Te has preguntado alguna vez ¿Cómo es que JavaScript se ejecuta?, ¿Cómo es que tu computadora logra entender el código que escribes? Bien, en este artículo te voy a explicar como es que ocurre este proceso y la serie de pasos que conllevan a que sea posible.
Este artículo está hecho para que logres entender varios de los aspectos internos de JavaScript y refuerces tus conocimientos en el lenguaje.
JavaScript Engine
Empecemos por entender que es el JavaScript Engine (motor de JavaScript). Básicamente es el encargado de que tu código escrito en JavaScript pueda ser interpretado por la computadora, ya que esta no entiende JavaScript como tal.

Se ejecuta en el navegador y el proceso que lo hace posible se le conoce como Just in time compiler que se traduce como "Compilación en tiempo de ejecución".

Engines destacados
A lo largo del tiempo han existido distintos javaScript engines, entre los más destacados tenemos a:
- V8: Creado por Google, usado por Brave, Chrome, Opera, Vivaldi y recientemente por Edge. También es usado por Node.js, Electron y ahora el famoso Deno.
- SpiderMonkey: Desarrollado por Mozilla y usado por Firefox.
- JavaScriptCore: El motor de Apple para Safari.
- Chakra: Creado por Microsoft para Internet Explorer y posteriormente para Edge antes de pasar a V8.
En este artículo hablaré principalmente del V8 Engine.
El escáner
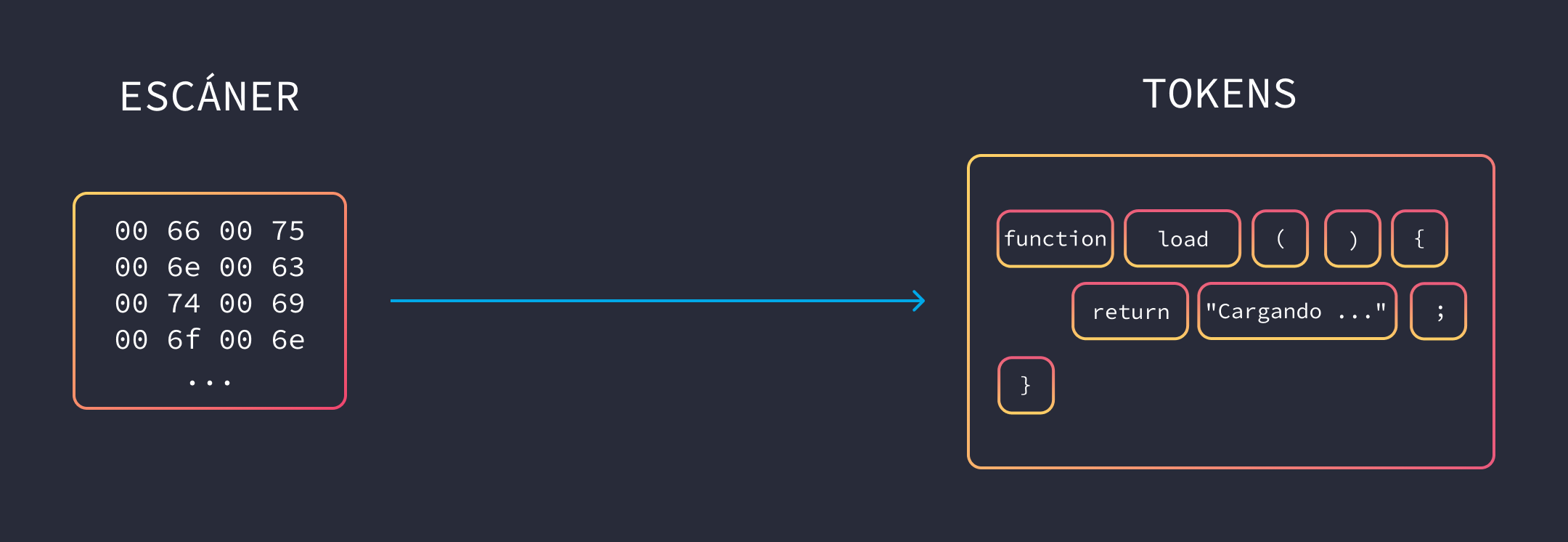
Todo comienza con la descarga del código fuente, en la etiqueta <script>. El código es consumido por un escáner en una secuencia de caracteres Unicode. Los caracteres Unicode se decodifican a partir de una secuencia de unidades de código UTF-16. El código puede ser traído localmente, desde la red, el caché o un service worker.

Tokens
Pasado este punto, lo siguiente es generar los tokens. Estos se crean a partir de la secuencia de unidades de código que teníamos previamente. Pueden ser una cadena, una función, un operador, etc. Digamos que son bloques creados a partir de tu código y que hacen referencia a lo que estás escribiendo.
Suponiendo que tienes el siguiente código:
function load() {
return "Cargando ...";
}Se generarían los siguientes tokens:
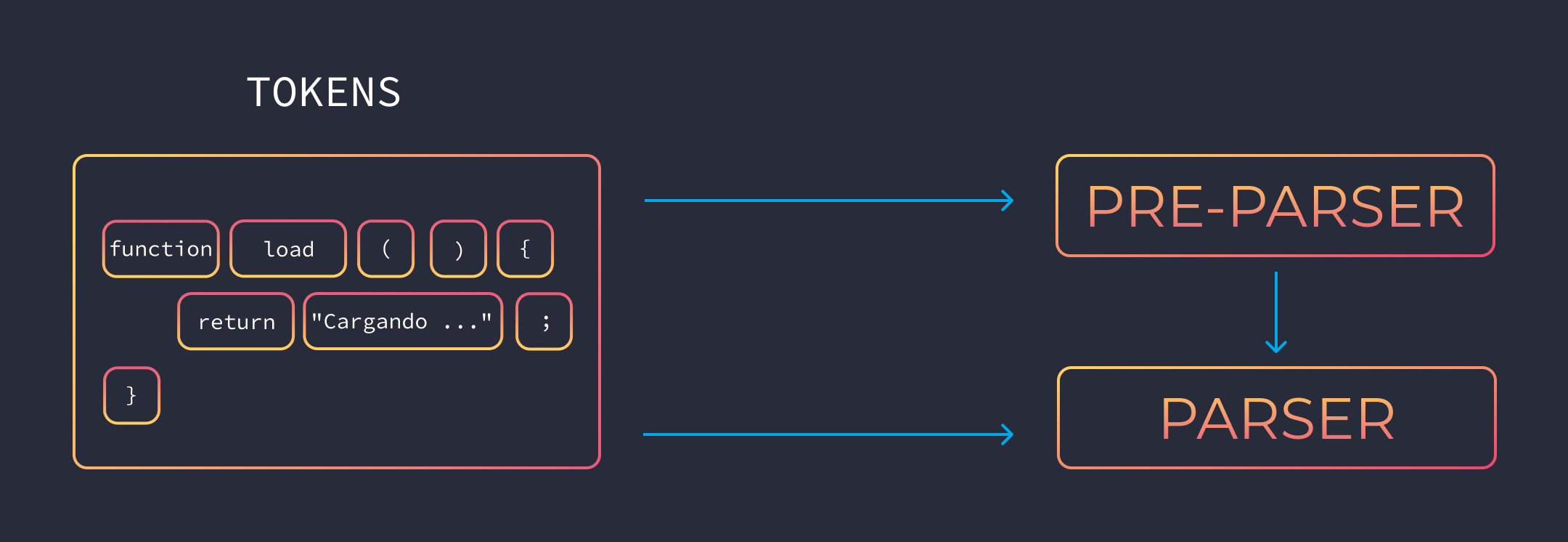
Parser y pre-parser
Los tokens son enviados a un parser y un pre-parser.
- El parser maneja el código que se necesita de inmediato, además se encarga buscar errores de sintaxis.
- El pre-parser maneja el código que se puede usar más adelante y encuentra solo un conjunto restringido de errores.
Con pre-parser y parser me refiero al pre-parseo y parseo. Podría ser algo como "pre-analizar" y "analizar".
Por ejemplo si tienes una función que se ejecuta después de un click, la función no se compilaría inmediatamente, sino que esperaría a que el usuario diera click para que el fragmento de código se envíe al parser.
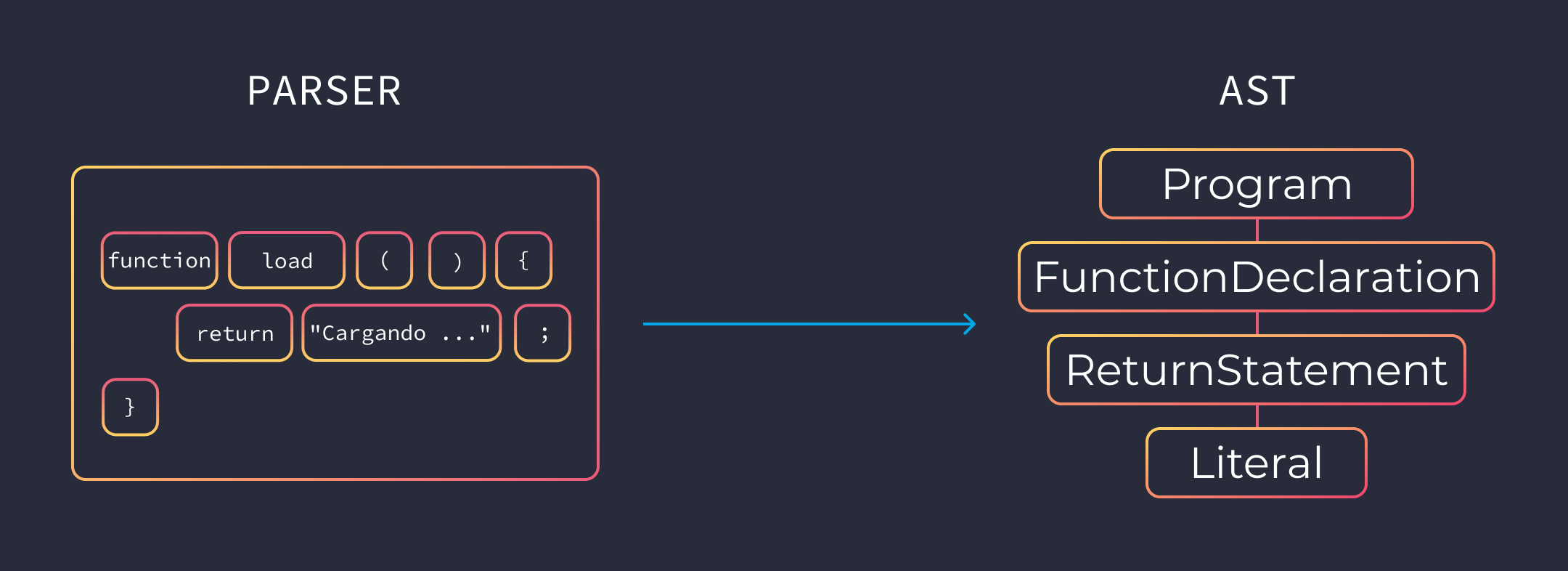
Abstract Syntax Tree
El parser crea nodos en función de los tokens. Con esos nodos se genera el Abstract Syntax Tree o AST. Un árbol que representa tu código sintácticamente, en términos simples, es una estructura de datos que se utiliza para representar el código fuente.
Por ejemplo para representar:
const a = 10;
Obtenemos:
{
"type": "Program",
"start": 0,
"end": 13,
"body": [
{
"type": "VariableDeclaration", // Se define que hay una declaración de variable
"start": 0,
"end": 13,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 12,
"id": {
"type": "Identifier",
"start": 6,
"end": 7,
"name": "a" // Con nombre "a"
},
"init": {
"type": "Literal",
"start": 10,
"end": 12,
"value": 10, // Valor de "10"
"raw": "10"
}
}
],
"kind": "const" // El tipo de variable es una "constante"
}
],
"sourceType": "module"
}
Siguiendo con el ejemplo de la función:
Intérprete
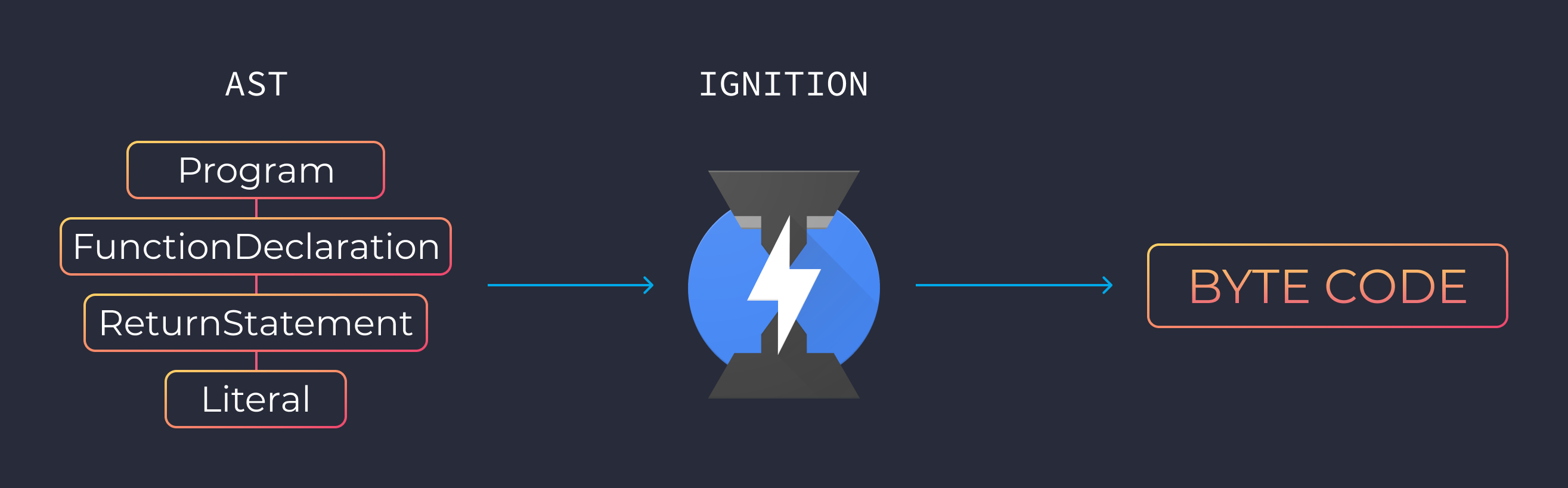
El intérprete recorre el AST y genera byte code basado en la información que contiene. Con esto finalmente tenemos algo que la computadora puede entender.
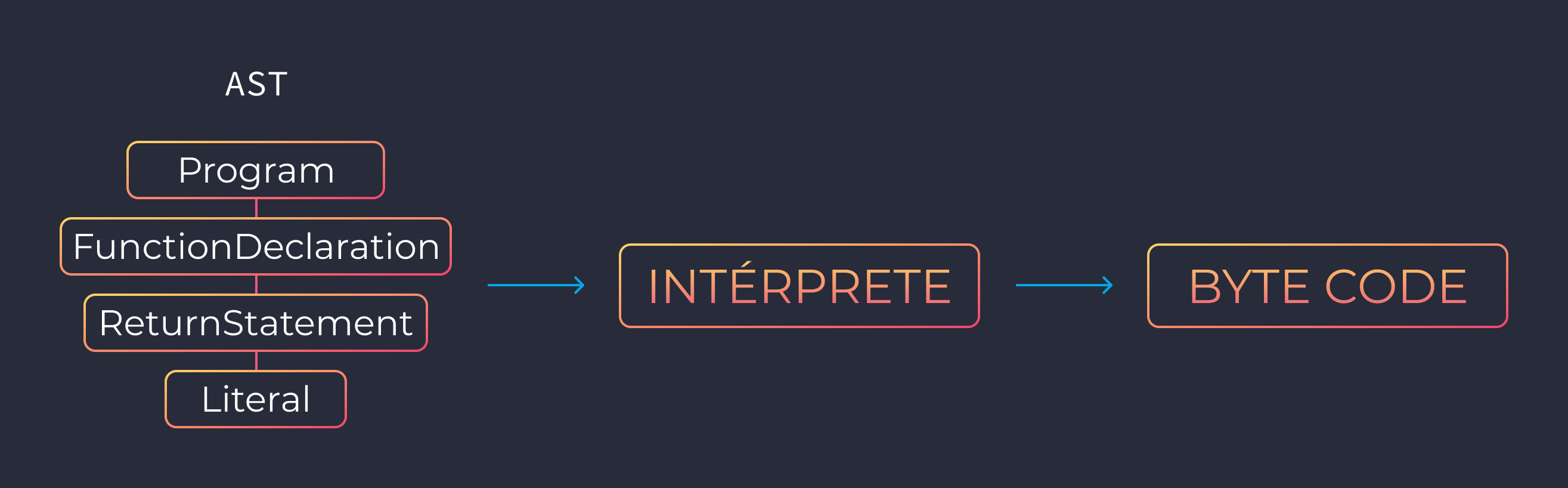
En V8 es un canal conocido como Ignition.
Profiler y compiler
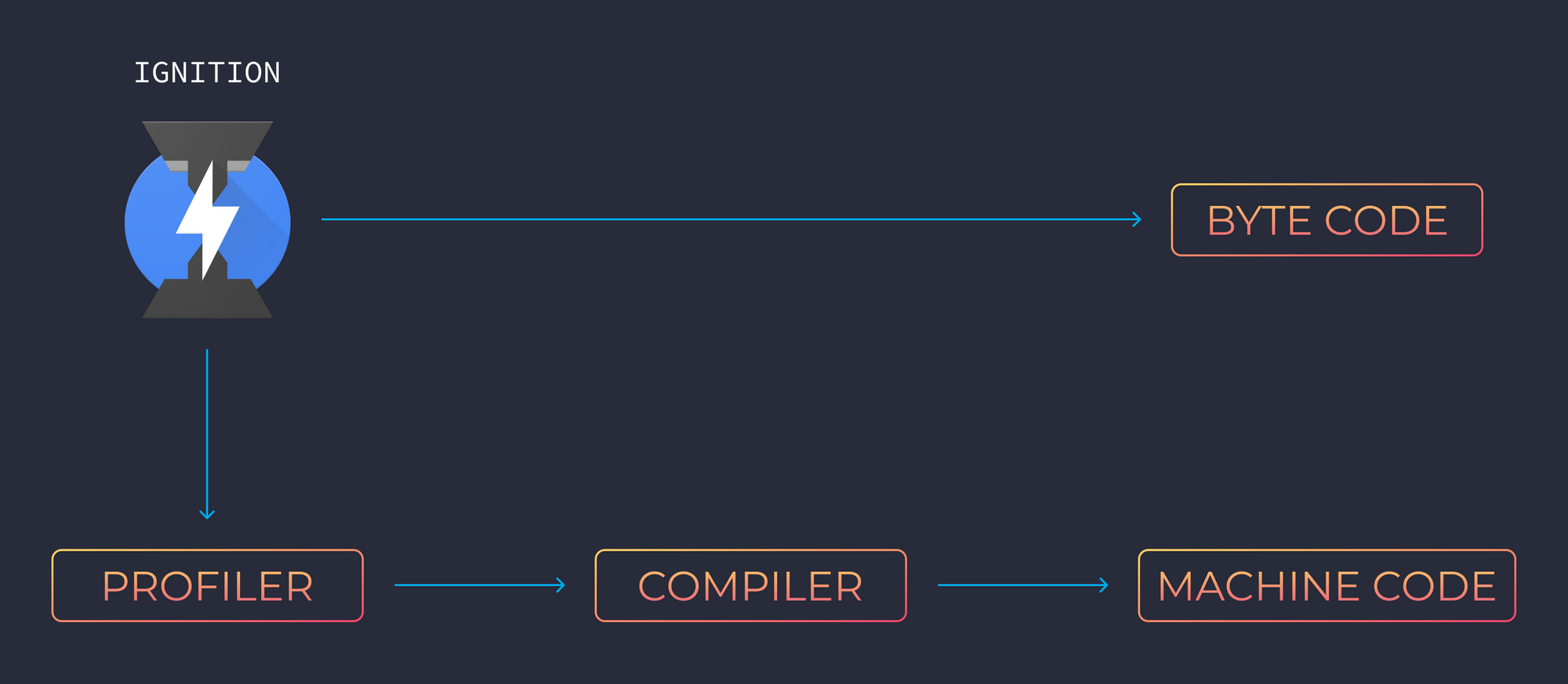
Puede que el código que esté recibiendo el intérprete no sea eficiente o que se estén repitiendo varios procesos. Aquí es cuando entra el profiler, que monitorea y mira el código para optimizarlo esto con el propósito de que todo funcione aún más rápido.
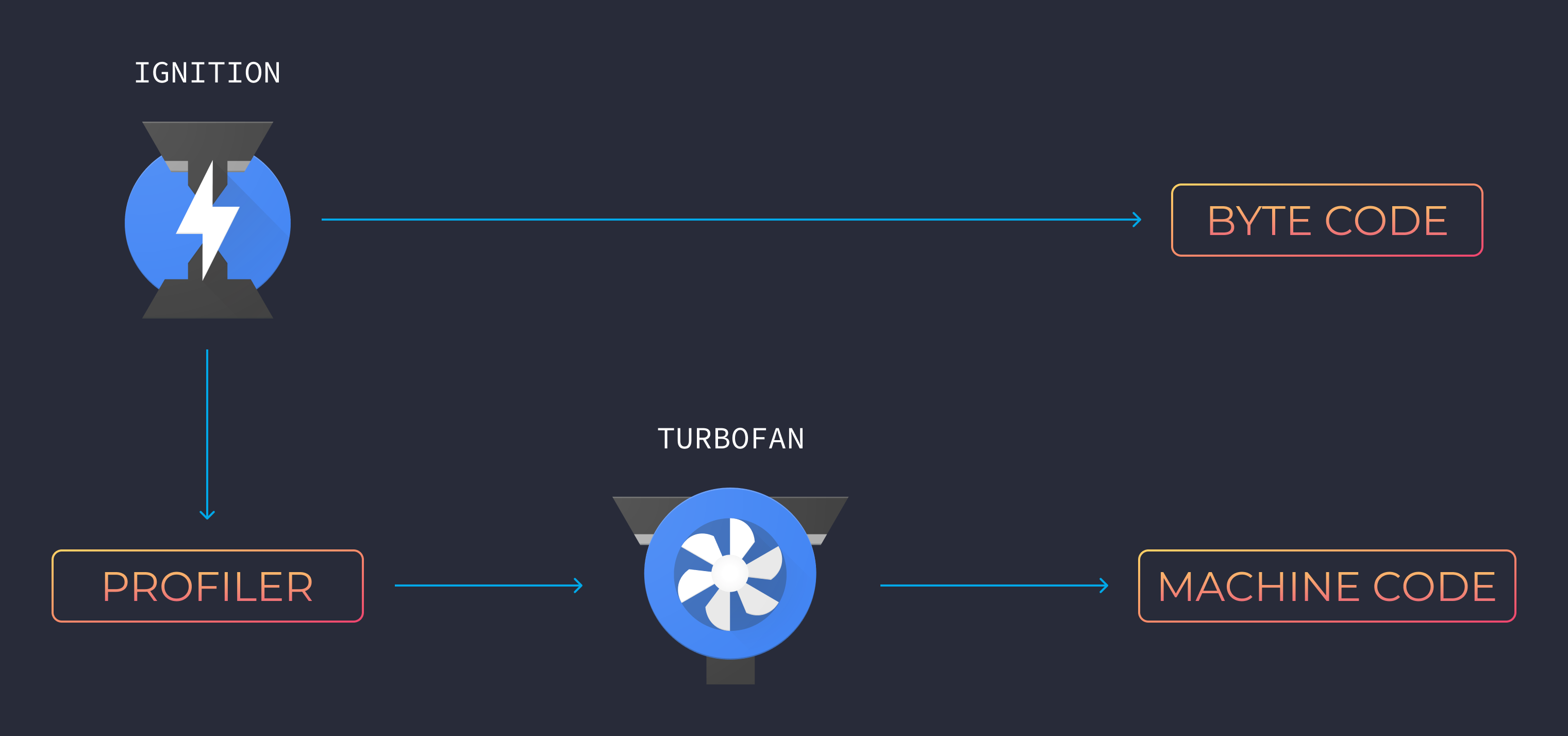
Una vez que se detecta el código que puede ser optimizado, es enviado al compiler (compilador) y se comienza a generar machine code (código maquina) altamente optimizado.
En V8 se le conoce como TurboFan.
He aquí la importancia de tener un buen código, mientras mejor sea, menor será el trabajo para el compilador.
Un ejemplo de código que se puede optimizar es una función que siempre regrese lo mismo y se esté llamando varias veces.
function multiplication() {
return 2 * 2;
}
multiplication();
multiplication();
multiplication();
Aquí la función estaría calculando la operación por cada ejecución, gracias al compilador se evita este comportamiento.
Como dato curioso, en los tres últimos pasos ocurre algo que en JavaScript se le conoce como Hoisting.
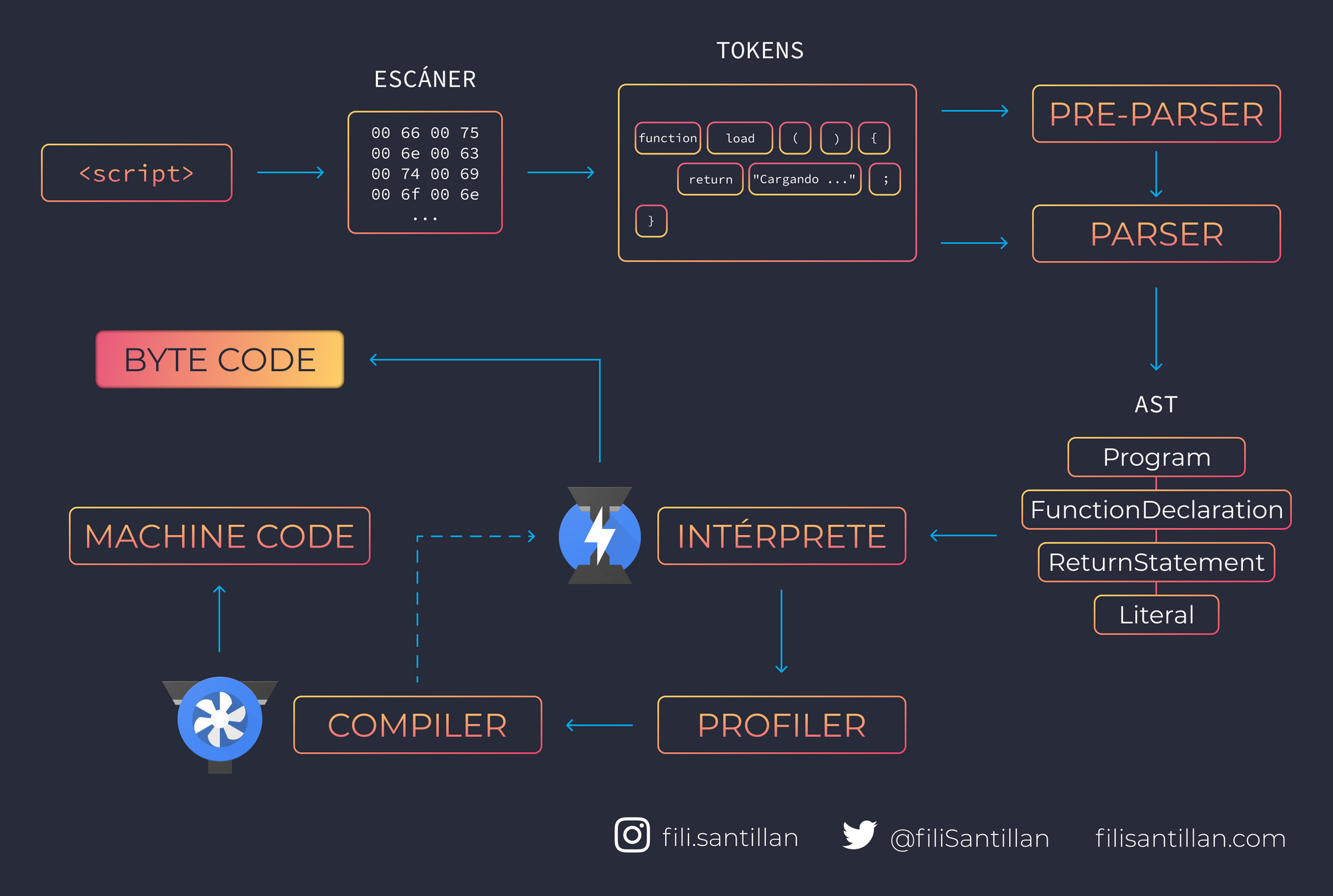
Recapitulando el JavaScript Engine tenemos lo siguiente:
- El escáner: Es el código consumido en una secuencia de caracteres Unicode que se decodifican a partir de una secuencia de unidades de código UTF-16.
- Tokens: Bloques creados a partir de tu código y que hacen referencia a que estás escribiendo.
- Parser y pre-parser: El parser maneja el código que se necesita de inmediato. El pre-parser maneja el código que se puede usar más adelante. Ambos identifican diferentes tipos de errores.
- AST: A partir de los nodos que genera el parser, se crea el AST. Un árbol que representa tu código sintácticamente.
- Interprete: El intérprete recorre el AST y genera byte code basado en la información que contiene.
- Profiler y compiler: El profiler monitorea y mira el código para optimizarlo. El compiler optimiza ese código y genera machine code.
¡Genial! Ahora sabes cómo funciona JavaScript por dentro. Aunque aún falta hablar de Memory Heap, Call Stack, JS Runtime, la asincronía de JS, etc. 🤯 Pero, esos temas se merecen un post propio. Por ello te recomiendo estar al pendiente de mis redes sociales y seas de los primeros de enterarse cuando se publique.
¡Espero que este post te haya sido útil!, recuerda que siempre puedes compartir tus dudas u opiniones en los comentarios, no olvides también ayudar a los demás.